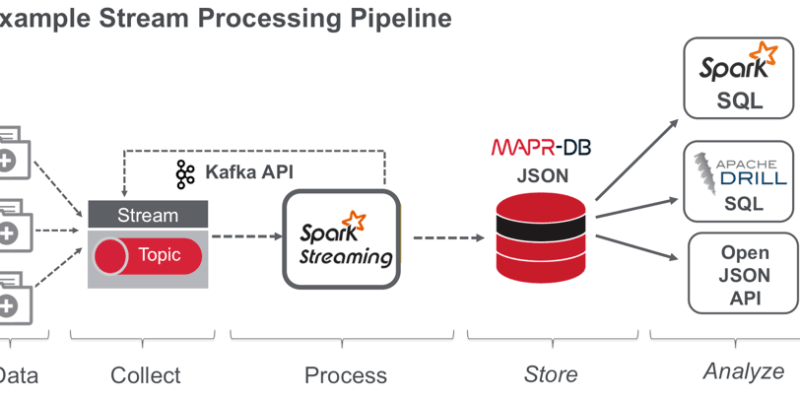
A streaming data pipeline is a system that collects, processes, and analyzes data as it is generated. This allows businesses to gain insights from their data in real time, rather than waiting for it to be stored in a data warehouse. Streaming data pipelines are becoming increasingly important as businesses generate more and more data.
Benefits of Streaming Data Pipelines
There are many benefits to using a streaming data pipeline. Some of the most important benefits include:
- Real-time insights: Streaming data pipelines allow businesses to gain insights from their data as it is generated. This can help businesses to make better decisions, improve customer service, and identify new opportunities.
- Reduced latency: Streaming data pipelines can reduce the latency between when data is generated and when it is analyzed. This can be important for businesses that need to react quickly to changes in the market or customer behavior.
- Increased scalability: Streaming data pipelines can be scaled to handle large amounts of data. This is important for businesses that are generating a lot of data, such as e-commerce businesses or social media companies.

Streaming Data Pipeline
Components of a Streaming Data Pipeline
A streaming data pipeline consists of the following components:
- Data sources: The data sources are the systems that generate the data. For example, data sources could be web servers, sensors, or social media platforms.
- Data ingestion: The data ingestion component collects the data from the data sources and stores it in a data buffer.
- Data processing: The data processing component analyzes the data in the data buffer and generates insights.
- Data storage: The data storage component stores the data that has been processed.
- Data visualization: The data visualization component displays the data in a way that is easy to understand.
Building a Streaming Data Pipeline
There are many different ways to build a streaming data pipeline. The best approach will depend on the specific needs of the business. However, there are some general steps that are involved in building a streaming data pipeline:
- Identify the data sources. The first step is to identify the data sources that will be used to generate the data for the pipeline.
- Collect the data. The next step is to collect the data from the data sources. This can be done using a variety of methods, such as web scraping, API calls, or sensor data collection.
- Store the data. The data that has been collected needs to be stored in a data buffer. This will allow the data to be processed in real-time.
- Process the data. The data in the data buffer needs to be processed. This can be done using a variety of tools, such as Apache Spark, Apache Kafka, or Google Cloud Dataflow.
- Store the processed data. The processed data needs to be stored in a data warehouse or data lake. This will allow the data to be analyzed for insights.
- Visualize the data. The data that has been stored in the data warehouse or data lake needs to be visualized. This will allow the business to gain insights from the data.
Conclusion
Streaming data pipelines are an important tool for businesses that want to gain insights from their data in real-time. By understanding the benefits of streaming data pipelines and the components that make up a streaming data pipeline, businesses can build a streaming data pipeline that meets their specific needs.









Comments